运输层概述
运输层位于应用层之下,它为应用程序的编写者提供了一套逻辑上“连接”的服务。对于开发者来说,他们只需要知晓一点点网络知识,(一般地)处理完程序逻辑之后便可将数据发送出去,然后等待对方的响应。运输层协议会自动处理连接中遇到的问题,并把无法处理的错误上报给调用者知晓。
网络层提供了主机之间的逻辑通信,而运输层为运行在不同主机上的进程之间提供了逻辑通信。
我个人觉得运输层协议的内容比往下的几层更复杂,这一层通常在操作系统内核中实现(书中用了端系统一词)。常见的运输层协议有TCP(Transmission Control Protocol)和UDP(User Datagram Protocol)。
我们先谈谈IP和端口,然后讲讲UDP,最后再说TCP吧。
IP和端口
IP地址,多数人都有个概念,主机上的每个网卡都拥有一个或多个地址。端口,是一个数字。非要作比喻的话,IP地址是小区楼的位置,而端口便是门牌号。一个端口占2字节。IP地址和端口是一对儿元素,知道了他们,便可以访问网络上绑定了这对地址和端口的程序了(这里有个特殊的情况,端口复用支持多个程序绑定一个端口)。 另一方面,传输层通过一个参数——端口,复用了主机之间的链路。书中将传输层封包(传输层打包数据,并交给网络层)的过程称为多路复用,将拆包(传输层从网络层大量数据中分离各包并传给相应应用程序)的过程称为多路分解。这两个定义是显然且自然的。
RFC1700 描述了一些常用的端口。
UDP协议
一段程序
我们先用 Python 简单地实现一个 example。
客户端(Client)程序:
1 | # udp_client.py |
服务端(Server)程序:
1 | # udp_server.py |
在网络程序中,总有一方先向另一方发送消息(打招呼),之后才开始交流。这两个程序开始的时候都申请了一个叫s的socket对象,便于后面管理。接着,服务端程序在本地地址127.0.0.1上绑定了自身端口10000。一般情况下,没有特殊需要时,客户端程序可以不绑定自己的地址,系统会自动分配一个。在第7行,客户端便向服务器所在(IP,Port)尝试发送用户输入的字符串。而服务端接收并显示。
UDP 报文
没有什么复杂的内容。整个过程里,我可以这样描述一个包(packet): (源地址 Source IP,源端口 Source Port,目的地址 Destination IP,目的端口 Destination Port, 内容 Message),或者这样写:
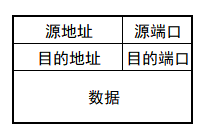
现在来认识一下UDP报文的结构:
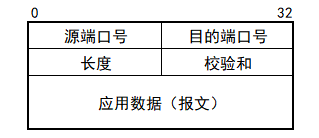
UDP 协议是较简单的运输层协议。对比上面两张图(第一张图包含的地址,是网络层的内容。前面说过,“网络层提供了主机之间的逻辑通信”),UDP 包只比我们需要的内容多了长度和校验和(又称检验和,checksum),其中长度指示了整个UDP包的长度。我们谈谈校验和。
UDP 校验和
校验和是通过UDP报文全文计算得来的2字节长度的值,和哈希类似,它生成数据的一个特征。人们总是寻找足够复杂的方法计算这一类的值,好让正常情况下数据损坏而校验和出现碰撞的几率大大降低。这样,当物理、链路、网络层次不小心损坏了数据时接收方能够发现,并采取补救措施。
UDP校验和的计算可以简要说明如下:
-
把所有要参与计算的数据,以16位(2字节)为单位相加,得到一个和。计算中任意一步遇到高位溢出时回卷,也就是计算结果加上刚溢出的1。
-
将第一步的和按位取反,即为校验和。验证的时候只需要再次计算一遍,并将所得的和与校验和相加,他们一定等于
~0(16bit的1)。注:在计算过程中,由于校验和未算出,所以校验和字段本身不参与计算(或者说先置为0再参与计算)。
引用《计算机网络:自顶向下方法》*(3.3.2 UDP Checksum)*的例子吧(之前怎么都没看懂):
举例来说,假定我们有下面3个16比特的字:
0110011001100000 ①
0101010101010101 ②
1000111100001100 ③
这16比特的前两个之和是: ① + ②
1011101110110101 ④
10100101011000001 ③ + ④(溢出)
则删去最高位的1,结果加上1。得到
0100101011000010
然后取反得到校验和。
更多计算方法在RFC1071中描述。
UDP 的特性
再回到我们刚才举例的程序,如果UDP报文在传输过程中出现差错,那么接收方的UDP协议代码能够通过校验和发现,然后将数据包丢弃。服务端程序不会知晓曾经到达一个出错的包,客户端(发送者)也不清楚投递是否成功。更进一步,如果网络中出现堵塞等情况,路由器不足以转发大量数据包的时候,路由器也会根据策略丢弃包(drop packet)而导致丢包(packet loss)。这在应用层调用者看来是莫名其妙,所以称UDP是不可靠的(不保证交付)。此外,通过UDP协议发送的数据还有不保证顺序、无连接的特点。
在我们的例子中,udp_client 向 udp_server 一条条地发送消息。如果 udp_server 某段时间无瑕应答,操作系统的 UDP 协议实现会将一些数据放到缓冲区(buffer)队列中。与TCP不同的是,UDP 协议不会将不同包合并,哪怕其中一些包来自同一个程序,这大概也是UDP名字中数据报(datagram)一词的缘由吧。在缓冲区满后,协议的实现会丢弃后来的包。
在这里我并不想过多地将UDP与TCP对比,尽管这些特性好像一直在说UDP怎么怎么不好。在这里我只能说,UDP是快速且便捷的,很多协议如域名解析(DNS)都基于它。
问题
好像网络中各层都给出了差错检测方案?
这个问题曾在知乎上看到过,贴一段《计算机网络:自顶向下方法》的话,是在UDP检验和这一节说的 :
你可能想知道为什么UDP首先提供了检验和,就像许多链路层协议(包括流行的以太网协议)也提供了差错检测那样。其原因是不能保证源和目的之间的所有链路都提供差错检测;这就是说,也许这些链路中的一条可能使用没有差错检测的协议此外,即使报文段经链路正确地传输,当报文段存储在某台路由器的内存中时,也可能引人比特差错。在既无法确保逐链路的可靠性,又无法确保内存中的差错检测的情况下,如果端到端数据传输服务要提供差错检测,UDP就必须在端到端基础上在运输层提供差错检测这是一个在系统设计中被称颂的端到端原则(end-end principle)的例子[Saltzer1984],该原则表述为因为某种功能(在此时为差错检测)必须基于端到端实现:“与在较高级别提供这些功能的代价相比,在较低级别上设置的功能可能是冗余的或几乎没有价值的。"
因为假定IP是可以运行在任何第二层协议之上的,运输层提供差错检测作为一种保险措施是非常有用的。虽然UDP提供差错检测,但它对差错恢复无能为力。UDP的某种实现只是丢弃受损的报文段;其他实现是将受损的报文段交给应用程序并给出警告。